近日,中國科學院合肥物質院智能所仿生智能中心陳雷團隊聯合上海人工智能實驗室與香港中文大學,提出一種面向大模型的低秩自適應微調框架GoRA,相關論文“GoRA: Gradient-driven Adaptive Low Rank Adaptation”被國際機器學習三大頂級會議之一NeurlIPS 2025高分(Average Rating:4.50)錄用。智能所碩士研究生何浩楠與香港中文大學博士后葉鵬為共同第一作者。
GoRA是一種全新的低秩自適應微調框架,旨在同時解決低秩微調方法LoRA中的兩個關鍵瓶頸問題:秩的選擇與權重初始化。現有方法通常僅優化其一,或在提升性能的同時犧牲效率與實用性,而GoRA創新性地利用預訓練權重的梯度信息,在訓練前動態分配每個適配器的最優秩,并以梯度壓縮為基礎對低秩矩陣進行自適應初始化。這一設計不僅避免了對原始預訓練權重的修改,徹底消除了訓練與推理之間的“權重不一致”問題,還顯著提升了微調性能,同時幾乎不增加額外的計算或內存開銷。值得一提的是,GoRA保持了與標準LoRA完全兼容的結構設計,可無縫集成到現有大模型訓練流程中,并支持分布式訓練。其引入的自適應梯度累積與縮放因子自動調優策略,進一步降低了超參數調優負擔,顯著提升了方法的“開箱即用”能力。
在多項基準實驗中,GoRA展現出卓越的泛化能力。在Llama3.1-8B-Base模型上進行數學推理微調時,GoRA以參考秩 r=8 的設定即超越標準LoRA達5.13個百分點(GSM8K);在更高秩設定下,其性能甚至反超全參數微調(full fine-tuning)2.05個百分點。此外,GoRA在自然語言理解(GLUE)、代碼生成(HumanEval)、對話評估(MT-Bench)以及圖像分類(CLIP-ViT)等多個任務和模態上均優于現有LoRA變體,驗證了其跨架構、跨模態的強大適應性。
此項研究不僅為大模型高效微調提供了新范式,也為未來面向資源受限場景的輕量化模型部署開辟了新路徑,具有重要的理論價值與應用前景。本研究得到國家重點研發計劃與國家自然科學基金的支持。
論文鏈接:https://openreview.net/forum?id=d1dL1ymD6N
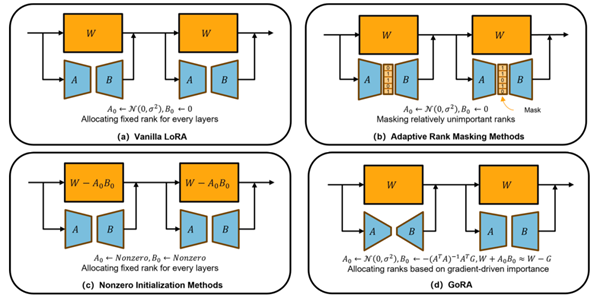
圖1 GoRA方法與其他方法的區別

<span id="9mlez"><optgroup id="9mlez"></optgroup></span>



