近日,中國科學院合肥物質(zhì)院智能所運動健康團隊丁增輝研究員聯(lián)合芝加哥大學、卡內(nèi)基梅隆大學團隊,在國際上首次提出一種多模態(tài)大模型視覺-語言預訓練方法RankCLIP,入選國際計算機視覺頂會ICCV 2025,彰顯了智能所在人工智能前沿領域的創(chuàng)新實力。智能所博士研究生張一鳴為第一作者。
自2021年OpenAI發(fā)布CLIP以來,視覺-語言模型始終依賴“圖像-文本一對一配對”的對比學習。盡管CLIP在零樣本分類、圖文檢索等任務中表現(xiàn)卓越,但其“硬對齊”方式也帶來明顯局限:模型僅能判斷“是否匹配”,卻無法理解“誰與誰更接近”。
RANKCLIP的核心突破在于:受人腦不同感官皮層和聯(lián)合皮層跨模態(tài)聯(lián)合表征機制啟發(fā),將訓練目標從Clip的“配對判斷”升級為“排序?qū)W習”,構(gòu)建圖像與文本之間的全局排序分布,并通過最大化排序一致性似然來優(yōu)化模型。該方法無需額外數(shù)據(jù)或計算資源,即可作為“即插即用”模塊融入現(xiàn)有CLIP系列模型,被大會程序委員會評價為“有望重新定義視覺-語言預訓練范式的突破性工作”。
該方法擁有三大技術創(chuàng)新:一是實現(xiàn)跨模態(tài)排序一致性,RankCLIP采用Plackett-Luce排序模型,將這一軟約束轉(zhuǎn)化為可導損失函數(shù),實現(xiàn)全局排序優(yōu)化;二是實現(xiàn)模態(tài)內(nèi)排序一致性,除了跨模態(tài)關系,RANRankCLIPKCLIP首次將圖像與文本各自內(nèi)部的語義排序納入訓練目標,有效挖掘了模態(tài)內(nèi)的潛在語義結(jié)構(gòu);三是設計動態(tài)權(quán)重系數(shù),漸進式權(quán)重策略使排序損失在訓練初期受噪聲影響較大,團隊設計動態(tài)權(quán)重系數(shù),使其在訓練過程中從零逐漸增大,既避免干擾初期的對比學習,又在后期充分釋放排序信號。
實驗結(jié)果證實RankCLIP全面刷新零樣本基準。零樣本分類:在ImageNet1K上,RankCLIP的Top-1準確率達到10.16%,顯著優(yōu)于CLIP(9.06%)、CyCLIP(9.40%)和ALIP(9.71%)。跨模態(tài)檢索:在MS-COCO圖像-文本檢索任務中,RankCLIP在多項召回率指標上均優(yōu)于基線模型。分布偏移魯棒性:在ImageNet-V2和ImageNet-R等具有自然分布偏移的數(shù)據(jù)集上,RankCLIP表現(xiàn)出更強的泛化能力。線性探測:在10個圖像分類數(shù)據(jù)集上的線性探測實驗中,RankCLIP平均準確率最高,顯示其表征學習能力的優(yōu)越性。
該創(chuàng)新成果的提出有利于推動醫(yī)療診斷、具身智能等關鍵領域的智能化升級,加速普惠AI技術的規(guī)模化落地,證明了算法創(chuàng)新優(yōu)于算力堆疊,展現(xiàn)了我國在大模型底層算法前沿研究領域的實力,也為全球AI技術的發(fā)展貢獻中國智慧。該研究得到了國家重點研發(fā)計劃計劃、安徽省科技攻堅等項目的支持。
ICCV(IEEE/CVF International Conference on Computer Vision)是計算機視覺領域最具影響力的國際頂級會議之一,也是中國計算機學會(CCF)推薦的A類國際學術會議。該會議每兩年舉辦一次,由美國電氣和電子工程師學會(IEEE)與計算機視覺基金會(CVF)聯(lián)合主辦。
論文鏈接:
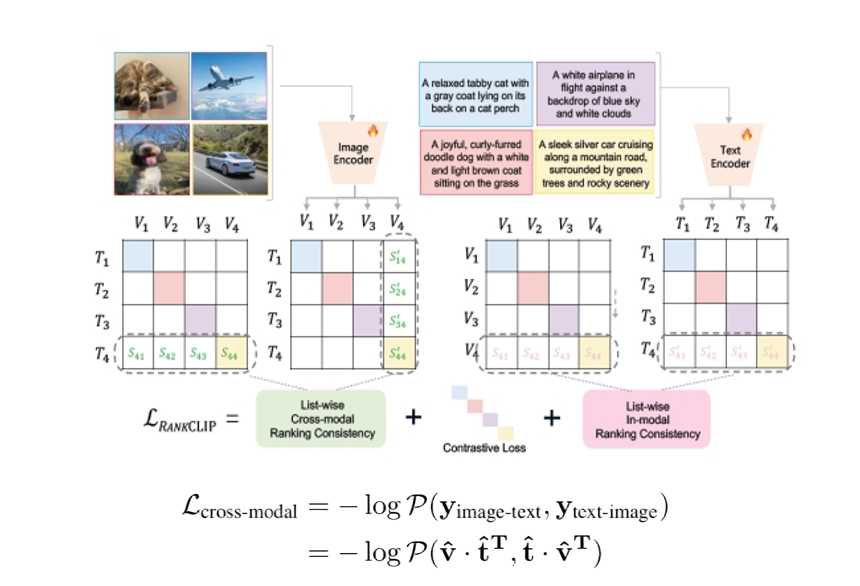
圖 RankCLIP技術概覽

<span id="9mlez"><optgroup id="9mlez"></optgroup></span>



