近日,中國科學院合肥物質院智能所運動健康團隊丁增輝研究員聯合芝加哥大學團隊,在國際上提出一種零樣本視頻理解動態令牌合并框架DYTO(Dynamic Token Merging framework for zero-shot video understanding),首次在視頻理解中系統引入了類腦式的動態選擇與壓縮機制,為解決“效率-語義”權衡問題提供了新路徑,為智慧醫療、在線視頻分析、人機交互等應用場景的高效AI落地奠定了技術基礎。該成果入選國際計算機視覺頂級會議ICCV 2025。
近年來,多模態大模型(MLLMs)極大推動了視頻理解的發展,但高效、精準的零樣本視頻理解仍面臨挑戰。傳統方法依賴大量標注數據和計算資源進行微調,而現有免訓練方法雖效率高,卻在復雜視頻中難以兼顧語義完整性與上下文連貫性。如何在計算效率與語義豐富性之間取得智能平衡,成為該領域的關鍵難題。
DYTO框架借鑒人腦處理視覺信息的核心機制,提出一種完全無需訓練的動態令牌合并方法。其突破在于通過“分層注意力選擇”與“自適應信息壓縮”兩大策略,在計算效率與語義理解之間實現高效平衡。DYTO可無縫接入現有圖像MLLMs,顯著提升零樣本視頻理解性能,并具備進一步強化已微調模型的潛力。該框架的技術創新主要體現在以下三個方面:首先,DYTO模擬人腦的對運動、高對比的信息的“選擇性注意力機制”,通過分層聚類分析視頻幀的語義表示(CLS令牌),自動識別并聚焦于關鍵事件片段,避免對冗余信息的均勻處理,實現高效的事件感知與時間結構建模。其次,受大腦信息壓縮與抽象記憶機制的啟發,DYTO采用動態二分圖令牌合并策略,依據每幀內容自適配地合并語義相近的視覺令牌,在減少計算負擔的同時,最大程度保留語義完整性,避免信息丟失與語義失真。最后,通過模仿大腦從局部到整體的認知過程,DYTO將分層聚類與令牌合并相結合,實現從幀級視覺特征到事件級語義結構的遞進式理解,增強對長視頻復雜內容的整體把握能力。
實驗結果證實DYTO全面刷新SOTA基準。在視頻問答任務的NExTQA、EgoSchema、MVBench等多個權威基準上,DYTO的表現全面超越了所有免訓練方法,甚至應用在圖像模型上也會優于許多經過視頻微調的模型。
博士研究生張一鳴為論文第一作者,丁增輝研究員為通訊作者。該研究獲國家重點研發計劃等項目支持。
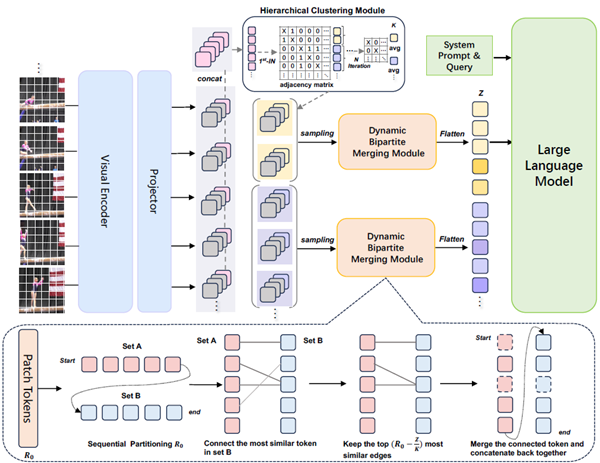
圖1:DYTO 技術框架的模型

<span id="9mlez"><optgroup id="9mlez"></optgroup></span>



