<span id="9mlez"><optgroup id="9mlez"></optgroup></span>
近日,中國科學(xué)院合肥物質(zhì)科學(xué)研究院健康所李海研究員團(tuán)隊(duì)在決策元控制的計(jì)算建模研究中取得關(guān)鍵性進(jìn)展。相關(guān)研究成果發(fā)表在認(rèn)知神經(jīng)科學(xué)的專業(yè)期刊Journal of Cognitive Neuroscience (JoCN) 上。
在日常生活中,人們經(jīng)常需要完成一系列決策以實(shí)現(xiàn)最終目標(biāo)。例如,在選擇餐廳時(shí),我們首先決定目的地和路線,而就餐后的體驗(yàn)會(huì)影響我們對(duì)餐廳的喜愛程度,進(jìn)而決定下一次的選擇偏好。然而,個(gè)體在進(jìn)行此類序貫決策時(shí)表現(xiàn)出顯著差異:有些人傾向于依賴習(xí)慣,選擇熟悉的選項(xiàng);而另一些人則更靈活,會(huì)根據(jù)當(dāng)前信息和目標(biāo)動(dòng)態(tài)調(diào)整選擇;更多的人則介于兩者之間。那么,習(xí)慣性和計(jì)劃性在序貫決策行為中的比重是如何決定的?這一問題是認(rèn)知神經(jīng)科學(xué)領(lǐng)域中的關(guān)鍵挑戰(zhàn)之一,即決策元控制中的仲裁機(jī)制。
通過行為實(shí)驗(yàn)和計(jì)算建模的方法,該研究揭示了:個(gè)體決策中習(xí)慣性策略(無模型強(qiáng)化學(xué)習(xí),model-free reinforcement learning)與目的性策略(基于模型的強(qiáng)化學(xué)習(xí),model-based reinforcement learning)的權(quán)重由可用的工作記憶資源決定。研究團(tuán)隊(duì)提出了一種新型混合強(qiáng)化學(xué)習(xí)模型(Hybrid-WM reinforcement learning model),將工作記憶資源的有限性納入決策機(jī)制的計(jì)算框架中。相較于傳統(tǒng)強(qiáng)化學(xué)習(xí)模型,該模型不僅能夠成功模擬任務(wù)負(fù)荷和延遲時(shí)間對(duì)決策行為的經(jīng)典影響,還能更精準(zhǔn)地?cái)M合實(shí)驗(yàn)數(shù)據(jù)。此外,該模型在獨(dú)立驗(yàn)證數(shù)據(jù)集上的表現(xiàn)進(jìn)一步支持其廣泛適用性。
本研究量化了工作記憶資源有限性在決策元控制中的核心作用及計(jì)算機(jī)制,為理解序貫決策行為提供了全新視角。這一發(fā)現(xiàn)不僅對(duì)認(rèn)知科學(xué)基礎(chǔ)研究具有重要意義,還為人機(jī)交互領(lǐng)域的創(chuàng)新應(yīng)用帶來啟發(fā)。此外,提出的混合強(qiáng)化學(xué)習(xí)模型為計(jì)算精神病學(xué)提供了新工具,有助于深入解析認(rèn)知障礙、精神障礙及神經(jīng)疾病患者在元控制機(jī)制中的缺陷,進(jìn)而為制定更精準(zhǔn)的診斷和干預(yù)策略提供理論依據(jù)。
該論文的第一作者為健康所碩士研究生左肇煜,通訊作者是李海研究員和楊立狀副研究員。本研究得到了國家自然科學(xué)基金、安徽省自然科學(xué)基金的支持。
文章鏈接:https://doi.org/10.1162/jocn_a_02237
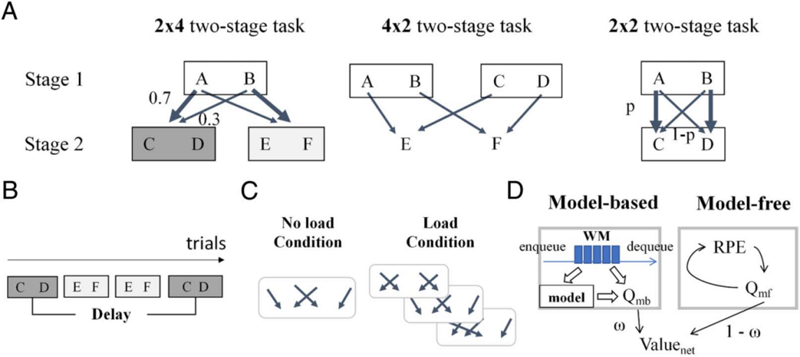
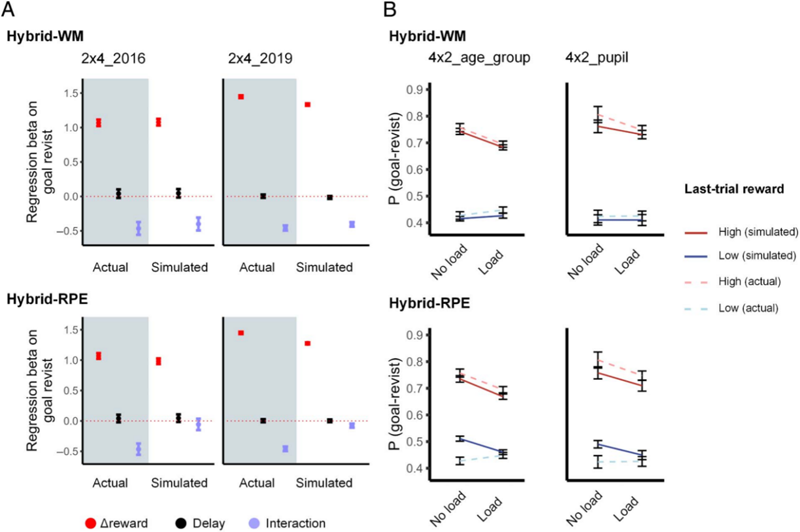
計(jì)算機(jī)制原理圖




